日本ジャーナリスト教育センター(JCEJ)が先日開催したワークショップ「
データジャーナリズム実践:Googleで社会を読み解く」では、Googleが提供するデータ分析サービス「Google Public Data Explorer」及び「Google Insights for Search」の使い方を学びました。今回はこれらを使い、よく耳にする「日本人は起業したがらない」は本当か、検証してみることにします。
なお、このテーマについては既に「Chikirinの日記」や「My Life After MIT Sloan」において優れた分析がなされていますが、ここではゼロベースで考えてみます。
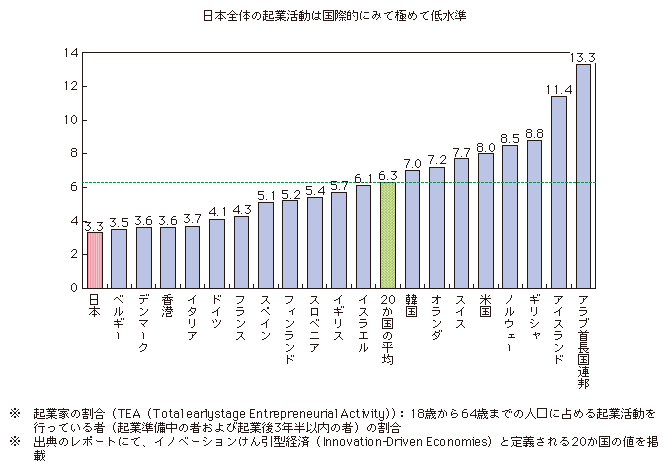
さて、少し古いデータで恐縮ですが、総務省が発行した2年前の情報通信白書によれば、2009年の日本における起業家の割合は、他の国に比べて低いようです。
我が国の起業の現状 | 平成22年版 情報通信白書
日本の起業活動については、2009年における生産を担う層に占める起業家の割合を主な20か国で比較すると、最下位といった状況がある。
この状況から「日本人は、他の国に比べて起業に対する意識は低い」とも考えられますが、実際どうなのでしょうか。
Google Public Data Explorerに
国別の起業動向や起業マインドに関する調査結果「Global Entrepreneurship Monitor (GEM)」のデータセットが公開されています。ここに国別の「Entrepreneurial Intention(起業する意思の度合い)」に関するデータが用意されていますので、これを使って2009年における日本と日本以外の国とを比較してみましょう。なお、Global Entrepreneurial Monitorについては、以下のスライドをご参照ください。
まず、世界における日本のポジションから。Google Public Data Explorerに用意されている4種類のグラフ「折れ線グラフ」「棒グラフ」「分布図」「バブルチャート」のうち、ここでは棒グラフで表現してみることにします。縦軸は労働人口に占める「起業したい」と考えている人の割合です。
日本のポジションは一目瞭然、かなり低いですね。サウジアラビア、ロシアに続き、下から3番目に位置しています。ちなみに一位(一番左)はウガンダで、上位はアフリカや南アメリカの国々が占めており、これらの地域に勢いがあることがわかります。
続いて時系列でもみてみましょう。今度は折れ線グラフで表現します。全ての国を表示させるとわかりにくくなるため、日本と、米国、そして中国を比較してみます。
残念ながらやはり日本人の起業に対する意識は、データが存在する2002年以降変わらず低いようです。米国人の意識はさほど高くない一方、中国人の意識はさすがに高いですね。
今度はバブルチャートを使い、少し複雑な分析をしてみましょう。バブルチャートでは4つの要素を同時に表現できるため、多面的に物事を捉えることができます。ここでは各要素の意味合いを以下の通り設定してみました。
- 横軸:全労働人口のうち、起業の機会があると考えている人の割合(Perceived Opportunities)。右にいくほど起業の機会があると考えている人の割合が高い。
- 縦軸:全労働人口のうち、起業するために必要なスキルは既に持っていると考えている人の割合(Perceived Capabilities)。上にいくほど起業のためのスキルを既に持っていると考えている人の割合が高い。
- 泡の色:全労働人口のうち、起業したいと考えている人の割合(Entrepreneurial Intention)。青は低く、赤が高い。赤に近づくほど起業したいと考えている人の割合が高い。
- 泡の大きさ:起業に対する恐怖心の大きさ(Fear of Failure Rate)。泡が大きいほど失敗の恐怖を大きく考えている人の割合が高い。
日本は突出して左下に位置し、泡の色は青で比較的大きいことから、
「起業の機会がない」「起業するために必要なスキルを持っていない」「起業したいと思っていない」「失敗するのが怖い」と考えている人が多数を占めているのがわかります。ただ、「失敗するのが怖い」のはどの国でもあまり変わらない(泡の大きさがあまり変わらない)ことから、それ以外の3要素に問題があるのでしょう。
ここまで、Google Public Data Explorerを使い、日本人は他の国とくらべて相対的に起業したがらない」傾向があることがわかりました。「Global Entrepreneurship Monitor (GEM)」のデータセットにはここで利用したものも含め、起業実態に関するデータが多数含まれていますので、他の視点から調査してみても良いかもしれません。
次にGoogle Insights for Searchを使い、日本人の意識を調査してみましょう。Google Insights for SeacheではGoogleで検索されたキーワードの頻出度(特定のキーワードが、いつ、どこで、どのくらい検索されたか)を調べられることから、キャンペーンやマーケティング施策の効果測定でよく利用されているようです。
ここでは「起業」というキーワードと、起業とは異なる就業形態である「就職(就職 + 就活 + 就職活動 + 転職)」というキーワードで比較してみます。
安定志向が強いせいか、やはり「就職」の方が圧倒的に検索されているようです。Google Insights for Searchでは伸び率も見ることができるため、こちらもチェックしておきましょう。
「就職」も減っていますが、「起業」はそれ以上に減っていいることがわかります。ここで、米国の状況とも比較しておきましょう。
米国でも「就職("job search" + "job hunting")」が減ってきているとはいえ「起業(entrepreneur)」もさほど多くはないことがわかります。しかしながら…
「起業」に対する意識は高まってきているようです。
以上、Google Public Data ExplorerとGoogle Insights for Searchを使い、「日本人は起業したがらない」は本当か、調査してみました。ここでの結果としては、
「日本人は起業したがらない傾向が強い」ぐらいは言えるのかもしれません。
最後にGoogle Correlateを使い、「どうすれば日本で起業が増えるのか」そのヒントを探ってみましょう。
Google Correlateでは相関が高い(検索傾向が似ている)検索キーワードのペアを見つけることができます。ここでは一つの仮説として、
日本人の「起業」に対する意識と相関が高いキーワードを見つけ、それを流行らすことができれば、自然と起業に対する意識も高めることができるのではないか、と考えてみます。
調べてみました。
「起業」はどうやら「
温浴」「
ゲルマニウム 温浴」そして「
キボンヌ」と相関が高いようです。日本にゲルマニウム温浴ブームを起こし、「キボンヌ」という言葉をみなが使うようになれば、起業する人が増えるのかもしれません。
みなさんも独自の分析を試みてはいかがでしょうか。以下、参考文献となります。